Жесткий диск - сложное электронно-механическое устройство, имеющее свою технологию самодиагностики, которая может предсказать о скором выходе из строя вашего жесткого диска. Что обычно является очень грустным событием...
Технология S.M.A.R.T. (англ. S elf M onitoring A nalysing and R eporting T echnology ) - технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Мы не будем рассматривать данную технологию во всех подробностях, т.к. это слишком широкий вопрос и у каждого из производителей накопителей своё видение и количество отслеживаемых параметров. Рассмотрим наиболее важные с практической точки зрения.
Для этого нам потребуется программа для просмотра отслеживаемых параметров.
В ней на вкладке "Хранение данных->SMART" выбираем жёсткий диск и в окне показываются отслеживаемые параметры:
01 Raw Read Error Rate - количество ошибок при чтении. У современных дисков очень большая плотность хранения данных, поэтому с ошибками они считывают данные постоянно, а информация восстанавливается за счёт кода коррекции ошибок ECC. Именно эти ошибки и считает этот параметр. В жёстких дисках фирмы Seagate эти некритичные ошибки показываются, остальные производители предпочитают об этом скромно умалчивать. Для дисков Seagate можно считать очень хорошим состояние когда параметры Raw Read Error Rate и Hardware ECC Recovered равны. Это значит что сколько было ошибок столько и было исправлено с помощью кода коррекции. Если же эти значения не равны то всё же не стоит бояться. Это не критичный параметр и диск может прожить ещё годы без каких либо проблем.
03 Spinup Time - время раскрутки диска до рабочего состояния. Беспокоиться стоит только если значение меньше половины от начального. Но тут ещё есть несколько нюансов, таких как сколько пластин в жестком диске. Максимум в настоящее время это 5 пластин (Hitachi), разумеется для раскрутки такого пакета дисков понадобится времени больше чем для 1-ой пластины. Силу инерции никто не отменял.
04 Start/Stop Count - общее количество стартов/остановок шпинделя. Для Seagate количество остановок шпинделя при переходе в режим энергосбережения.
05 Reallocated Sector Count - число переназначенных секторов. То есть когда диск обнаруживает ошибку чтения/записи, он помечает сектор «переназначенным», и переносит данные в специально отведённую резервную область. Вообще это страшный параметр, если значение его равно более 10 то это как минимум значит что пора вроверять всю поверхность диска чтобы понять будет ли этот процесс продолжаться. Судя по практике переназначенными секторами страдают ноутбучные диски гдето через год использования. Потому как они работают в очень жестких условиях. Я не говорю об ударах - большинство от этого более-менее защищены. Причина - температура. Корпус ноутбука обычно плохо продувается и диск перегревается, затем мы выключаем ноутбук и идём куда? Ну правильно, на улицу! А там -10 по цельсию. Вот как раз скорость нагрева-остывания и разрушает нежный магнитный слой на пластинах диска. По спецификациям всех производителей дисков так называемый "временной градиент температур", то есть скорость изменения температуры должна быть не более 20 град/час - в рабочем состоянии и не более 30 град/час в выключенном. Это правило нарушается всегда, но для ноутбуков особенно часто и жестоко.
09 Power-on Time Count (Power-on Hours) - количество времени проведённого во включённом состоянии. Обычно у современных дисков измеряется в часах (у Fujitsu в секундах). У старых дисков Maxtor, не у тех которые сейчас выпускаются Seagate под этой маркой, а у оригинальных Maxtor время изменяется в минутах. Это весьма полезный параметр если вы покупаете старый диск, то хочется же знать сколько он в своей жизни отработал. А кроме того обычно это время совпадает с временем работы компьютера и можно определить сколько человек проводит за компьютером в среднем. Как показывает практика и мой опрос на одном из крупных форумов посвящённых компьютерному железу диски с временем наработки более 20000 часов (примерно 2.5 года постоянной работы) уже имеют какие то дефекты, например те же "переназначенные" секторы и не так уж далеки от старческой смерти. Из тех же спецификаций производителей можно узнать что диски предназначенные для настольных компьютеров не предназначены для круглосуточной работы, а рассчитаны на работу в режиме 8/5, то есть 8 часов 5 дней в неделю. Это получается около 2400 часов в год. И получается что гарантия рассчитана для 3-х лет - 7200 часов, для 5 лет - 12000 часов. Не так то уж и много, учитывая что в году 8760 часов.
0A Spinup Retry Count - Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то вероятнее всего повреждение механической части/подшипников. Встречается очень редко, современные диски делают с гидродинамическими подшипниками и в случае неисправности такого подшипника он заклинивает сразу и намертво или работает долго и счастливо. Не так давно этим сильно страдали диски Toshiba и в меньшей степени Western Digital. Заклинивание происходит от перегрева.
0С Power Cycle Count - число циклов включения/выключения диска.
С2 Temperature - температура диска. К сожалению датчики температуры стоят у дисков разных производителей в разных местах, поэтому бывают и завышения и занижения реальной температуры. Но в среднем как показало недавнее исследование Google оптимальная рабочая температура находится в пределах от 35 до 45 градусов. Выше 50 градусов эксплуатация крайне не рекомендуется, но такую температуру и даже выше часто можно увидеть в ноутбуках.
Число секторов, являющихся кандидатами на замену. Они не были ещё определены как плохие, но считывание с них отличается от чтения стабильного сектора, это так называемые подозрительные или нестабильные сектора. В случае успешного последующего прочтения сектора он исключается из числа кандидатов. В случае повторных ошибочных чтений накопитель пытается восстановить его и выполняет операцию переназначения. Значение не равное нулю встречается обычно если на диске уже есть переназначенные сектора. Если это так, то с высокой вероятностью можно сказать что диск активно "сыпется", то есть разрушается магнитный слой пластин жесткого диска.
Кол-во нескорректированных ошибок, то есть серьёзное повреждение поверхности диска. Появляются такие ошибки когда заканчивается место в резервной зоне диска для переназначения секторов. Так же могут появляться при резком отключении питания в момент когда диск записывает данные - это так называемые "программные бэд блоки". Если их количество один два, а остальные параметры касающиеся поверхности диска в норме то беспокоиться не стоит. Если же велико, то данные надо спасать и готовить "тело на вынос". :)
С7 Ultra ATA CRC Error Rate - количество ошибок при передаче во внешнем интерфейсе. Обычно в этом виноват кабель или плохой контакт кабеля с разъёмами, особенно проявляется на SATA дисках. Встречается весьма часто.
С8 Write Error Rate - ошибки при записи на диск. Встречается редко. Обычно на очень старых дисках. Если есть ошибки то это означает физический износ привода головок жесткого диска. Или же при серьёзных повреждения поверхности диска. (когда количество переназначенных секторов и нескоректированных ошибок превышают все разумные значения).
Вот мы и кратенько рассмотрели основные параметры системы самодиагностики жестких дисков. Если есть желание узнать об этом подробнее то можно обратиться к материалам википедии:
К сожалению SMART не всегда может предсказать смерть диска. Как показало исследование всё того же Google около 50% дисков умирают резко и без видимых причин. Но в одном эта технология точно полезна. По ней можно быстро узнать состояние поверхности диска, то есть параметры:
05 Reallocated Sector Count
C5 Current Pending Sector Count
С6 Offline Uncorrectable Sector Count
И очень полезно знать время которое за свою жизнь проработал диск, чтобы примерно угадать что от него можно ждать.
А теперь немного о будущем. В продаже уже появилось достаточное количество предложений действительно "жестких дисков" . Они выполнены на микросхемах твердотельной памяти типа flash и гораздо более надёжны и по механическим воздействиям и по температуре. Однако производители ещё не договорились о стандарте системы самодиагностики для этого вида накопителей. Но она будет гораздо проще чем для старых добрых электромеханических дисков. И главное с гораздо более высокой вероятностью будет предсказывать возможность выхода из строя! Флэш память более предсказуема в этом смысле. Чтож, будем ждать этого светлого будущего!
Что такое SMART HDD (жёсткого диска) и что нужно делать, если компьютер выдаёт надпись «smart status bad backup and replace».Во всех современных накопителях последних лет абсолютно любого производителя присутствует система SMART (self-monitoring, analysis and reporting technology - технология предупреждения, анализа и самопроверки) жесткого диска, очень тесно связанная с функционированием накопителя.
Современные технологии SMART осуществляют: мониторинг различных параметров состояния диска, сканирование поверхности жесткого диска с дальнейшей автоматической заменой нечитаемых секторов и занесение их в error-log, т.н. список, где номера этих секторов хранятся в виде таблицы, периодическое повторное сканирование "ненадежных" секторов из error-log и, если система определяет, что данный сектор исправен - то исключает его из данного списка и он становится доступен на поверхности для пользовательской информации (но также помечается для дальнейшей перепроверки при следующем сканировании поверхности), либо, если сектор не прочитывается несколько раз подряд, не переписывается, то он отправляется в следующий дефект-лист,именуемый у разных производителей по-разному, но имеющий одинаковое предназначение - этот лист является как бы посредником между error-log таблицей и финальным G-листом, где дефект уже будет занесен в G-лист навсегда, станет отображаться в SMART, в строке current pending sectors/offline UNC sectors.
Из статуса current pending поврежденный сектор после очередной перепроверки на "живучесть", если не прошел чтение/запись, то окончательно отправляется в статус переназначенных и там уже остается. Диск в дальнейшей работе его уже не использует, не тестирует повторно на чтение/запись.
В строке reallocated sector count изменяется значение с N на N+1.
Если накопитель имеет уже серьёзные повреждения, то при загрузке компьютера может выводиться надпись: «smart status bad backup and replace». Это значит, что статус SMART жёсткого диска изменился из состояния GOOD в состояние BAD, на диске как минимум имеются BAD-блоки и состояние диска продолжает ухудшаться. Пользователю рекомендуется сохранить свои данные, если они ещё доступны для чтения и заменить жёсткий диск на новый.
SMART ВЫГЛЯДИТ ТАК:
Выводится в виде таблицы со следующими столбцами:
ID – ИДЕНТИФИКАЦИОННЫЙ НОМЕР ПАРАМЕТРА
Name – выводимое программой имя параметра
VAL – НОРМАЛИЗОВАННОЕ ЗНАЧЕНИЕ ПАРАМЕТРА (НОРМАЛИЗОВАННОЕ ЗНАЧИТ, В ДАННОМ СЛУЧАЕ, ЧТО ВНУТРЕННЕЕ (RAW) ЗНАЧЕНИЕ ПАРАМЕТРА ПРЕОБРАЗОВАНО ПО ОПРЕДЕЛЁННОМУ АЛГОРИТМУ ДЛЯ БОЛЕЕ УДОБНОГО И ПОНЯТНОГО ПРОСМОТРА ЗНАЧЕНИЯ. НАПРИМЕР, ВНУТРЕННИЙ ПАРАМЕТР ВСЕГДА УВЕЛИЧИВАЕТСЯ И МОЖЕТ ПРИНИМАТЬ ЗНАЧЕНИЕ В НЕСКОЛЬКО ТЫСЯЧ ЕДИНИЦ, А ВЫВОДИМОЕ ЗНАЧЕНИЕ ИЗМЕНЯЕТСЯ ОТ 100 ДО 0 И ОТОБРАЖЕНИЕ ВНУТРЕННЕГО ДИАПАЗОНА ИЗМЕНЕНИЯ ПАРАМЕТРА НА ВЫВОДИМЫЙ И ЕСТЬ, В ДАННОМ СЛУЧАЕ, НОРМАЛИЗАЦИЯ)
Wrst – худшее значение параметра за отрезок времени время
Thresh – пороговое значение, при достижении которого диск рекомендуется заменить
РАССМОТРИМ, КАКИЕ СУЩЕСТВУЮТ ПАРАМЕТРЫ В СИСТЕМЕ SMART. НАБОР ОТСЛЕЖИВАЕМЫХ ПАРАМЕТРОВ ЗАВИСИТ ОТ ПРОИЗВОДИТЕЛЯ ДИСКА И НЕ ВСЕ ИЗ ПЕРЕЧИСЛЕННЫХ БУДУТ ПРИСУТСТВОВАТЬ В ВАШЕМ СЛУЧАЕ.
Атрибуты SMART:
1 Raw read error rate - количество ошибок при считывании секторов с пластин.
2 Throughput Performance - общая производительность диска в относительных единицах.
3 Spin-up time - время раскрутки пластин от нуля до номинальной скорости вращения в миллисекундах
4 Number of spin-up times - количество циклов раскрутки/остановки пластин; отражает механический ресурс диска из-за ограниченного количества циклов запуска/останова.
5 Reallocated sector count - параметр отражает количество запасных секторов; когда диск находит ошибку чтения/записи/проверки, он переназначает плохой сектор на хороший из запасной зоны; нормализованное значение атрибута уменьшается по мере убывания запасных секторов; RAW-значение показывает количество преназначенных секторов, которое в норме должно быть ноль; на SSDRAW значение показывает количество неисправных блоков флеш-памяти.
6 Read Channel Margin - данный атрибут не используется в современных накопителях.
7 Seek error rate - количество ошибок позиционирования магнитных головок.
8 Seek Time Performance - средняя скорость позиционирования привода магнитных головок на указанный сектор; в SSDпараметр не используется
9 Power-on time - ожидаемое время жизни диска, основанное на времени, проведённом во включённом состоянии; нормализованное значение уменьшается со 100 до 0, связано с ресурсом диска; уменьшение этого параметра косвенно говорит о состоянии механики диска
10 Spin-up retries - количество попыток раскруток пластин при условии, что первая попытка была неудачная; считается с момента начала использования; на SSD не используется
12 Start/stop count - ожидаемое время жизни, основанное на количестве пусков/остановов пластин; каждый диск имеет ограниченное количество пусков/остановов, параметр уменьшается со 100 до 0; RAW значение показывает число включений/выключений
13 Soft Read Error Rate - у одних производителей этот параметр описывается, как указывающий на количество ошибок, не восстановленных ECC, а у других наоборот - восстановленных
100 Erase/Program Cycles - общее количество циклов чтения/записи для всей флеш-памяти за весь срок службы; SSD имеет ограничение на количество циклов чтения/записи, конкретное значение зависит от типа и производителя микросхем флеш-памяти
103 Translation Table Rebuild - количество событий перестроения внутренней таблицы адресов блоков при её повреждении и восстановлении; RAW значение показывает актуальное количество данных событий
170 Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
171 Program Fail Count - количество случаев неудавшейся записи блока флеш-памяти
172 Erase Fail Count - количество случаев неудавшейся операции стирания блока флеш-памяти
173 Wear Leveller Worst Case Erase Count - максимальное количество операций стирания, произведённых над блоком флеш-памяти
178 Used Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
180 Unused Reserved Block Count - описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество неиспользованных резервных блоков
183 SATA Downshifts - показывает, как часто требовалось понизить скорость передачи по SATA (с 6Гб/c до 3Гб/с или 1.5Гб/с) для успешной передачи данных, при уменьшении значения атрибута следует заменить кабель
184 End-to-End error - количество ошибок, возникших в буфере диска; часть технологии HP SMART IV; может свидетельствовать о неисправности RAM-буффера диска
185 Head Stability - по атрибуту нет достоверной информации
186 Induced Op-Vibration Detection - по атрибуту нет достоверной информации
187 Reported UNC error - количество нескорректированных ошибок чтения
188 Command timeout - количество невыполненных диском команд из-за истечения времени ожидания
189 High Fly writes - количество ошибок записи, вызванных неправильной высотой полёта магнитной головки над поверхностью
190 Airflow temperature - температура воздуха внутри гермоблока HDD
191 G-Sense Errors - указывает сколько раз диск прерывал работу из-за ударов или вибрации
192 power-off retract cycles - количество неожиданных пропаданий питания, когда оно пропадало прежде, чем была получена команда на отключение диска; у hdd срок службы при неожиданном отключении значительно меньше, чем при нормальном; у ssd есть риск потери таблицы внутреннего состояния при неожиданном пропадании питания
193 load/unload cycles - количество перемещений бмг между зоной парковки и зоной данных; значение уменьшается от 100 до 0, raw содержит актуальное количество перемещений
194 hda temperature- температура блока магнитных головок
195 hardware ecc recovered- количество ошибок чтения, скорректированных кодом коррекции ошибок
196 reallocation events - общее количество переназначений секторов, включает и off-line сканирование и обычную работу
197 current pending sectors- количество нестабильных секторов, ожидающих перепроверки и, возможно, переназначения
198 offline scan unc sectors- количество плохих секторов, найденных диском при фоновом самосканировании; ухудшение этого параметра говорит о быстрой деградации поверхности
199 ultra dma crc errors- количество ошибок при передаче данных между диском и материнской платой; при ухудшении этого параметра стоит заменить кабель
200 write error rate - частота возникновения ошибок при записи
202 data address mark errors - количество ошибок при поиске запрошенного сектора
203 run out cancel - количество ошибок, вызванных неверной контрольной суммой при попытке коррекции ошибки
204 soft ecc corrections - количество ошибок, скорректированных кодом коррекции
206 flying height - девиация высоты полёта головки над поверхностью относительно оптимального значения; если головка слишком низко, она может повредить поверхность, если слишком высоко - увеличивается количество ошибок чтения
207 spin high current - величина тока, требуемая для раскрутки пластин
209 offline seek performance - производительность подсистемы поиска при выполнении off-line сканирования
220 disk shift - расстояние, на которое сместился пакет пластин относительно теоретического положения в результате механического повреждения или перегрева
227 torque amplification count - показывает сколько раз требовалось подавать увеличенный ток для раскрутки пластин
230 gmr head amplitude - амплитуда колебаний головок бмг
233 media wearout indicator - остаток ресурса памяти в ssd
240 head flying hours- время, проведённое головками в зоне пользовательских данных; значение уменьшается, обычно от 100 до 0
241 total lbas written - количество 512-и байтных блоков, записанных за всю жизнь устройства
242 total lbas read - количество 512-и байтных блоков, считанных за всю жизнь устройства
250 read error retry rate
Сложность интерпретации значений smart состоит в том, что ни на количество, ни на тип, ни на значения, ни на единицы измерения отслеживаемых параметров нет единого стандарта. поэтому реализация smart всегда зависит от конкретного производителя. нормализацию raw-значений в показатели атрибутов все делают по-своему, а результатом является статус проверки smart good или bad. поэтому достоверный вывод о состоянии диска можно сделать только проверив его поверхность какой-либо диагностической программой. но если нужно быстро оценить состояние диска и возможные проблемы, нужно обратить внимание на несколько основных, самых информативных атрибутов.
Наиболее важные аттрибуты smart:
5 reallocated sectors count - количество переназначенных секторов; рост значения этого атрибута свидетельствует об ухудшении состояния поверхности диска
Современные жесткие диски довольно “умные” устройства и, кроме основных присущих им как устройствам хранения и обработки данных свойств, поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (S elf-M onitoring A nalysis a nd R eporting T echnology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков (HDD). В последующие годы стандарты S.M.A.R.T дорабатывались в соответствии с изменениями технологий и оборудования (SMART II и SMART III) и продолжают совершенствоваться в настоящее время.
Жесткий диск, начиная с момента его изготовления, постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках - атрибутах (Attribute), сохраняющихся в постоянном запоминающем устройстве, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя - служебной зоне . Данные атрибутов могут быть считаны, в соответствии со спецификацией ATA (AT A ttachment) по командам поддержки SMART (SMART READ DATA и еще более десятка команд), которые передаются в накопитель специальным программным обеспечением, как например, утилитами от производителей оборудования или универсальными программами тестирования и мониторинга состояния HDD (udisks, smartctl, GSmartControl, gnome-disks и т.п.). Современные стандарты ATA включают в себя поддержку протокола SCT (SMART Command Transport), обеспечивающего считывание журналов статистики устройства. Журнал статистики устройства - это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG.
Атрибут представляет собой характеристику определенного состояния жесткого диска, которая изменяется в процессе эксплуатации, принимая числовое значение от максимального, установленного в момент изготовления данного устройства, до минимального, при достижении которого, работоспособность накопителя не гарантируется. Все атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется жесткими дисками разных моделей. Некоторые из них могут использоваться только конкретным производителем оборудования, и поддерживаться отдельными моделями накопителей. Так, например, атрибут с идентификатором 7 , характеризующий количество ошибок установки головок на требуемую дорожку поверхности дискаSeek_Error_Rate не имеет смысла для твердотельных дисков (SSD) и, соответственно, не поддерживается ими, а атрибут с идентификатором 9 ,характеризующий суммарное время работы накопителя за весь срок эксплуатации и обозначаемый как Power_On_Hours ,поддерживается как SSD, так и традиционными HDD.
Атрибуты состоят из нескольких полей, (наиболее часто обозначаемых как Val, Worst, Tresh, RAW ), каждое из которых является определенным показателем, характеризующим техническое состояние накопителя на данный момент времени. Программы считывания S.M.A.R.T. выводят содержимое атрибутов, как правило, в виде нескольких колонок:
Pre-Failure (PF, 01h)
- при достижении порогового значения данного типа атрибутов диск требует замены. Иногда данный бит флагов обозначают как Life Critical (CR)
или Pre-Failure warranty (PW)
O
nline test (OC, 02h)– атрибут обновляет значение при выполнении off-line/on-line встроенных
тестов SMART;
P
erfomance R
elated (PE или PR , 04h)– атрибут характеризует производительность;
E
rror R
ate (ER , 08h)– атрибут отражает счетчики ошибок оборудования;
E
vent C
ounts (EC, 10h) – атрибут представляет собой счетчик событий;
S
elf P
reserving (SP, 20h) – самосохраняющися атрибут;
Некоторые из программ могут интерпретировать флаги в виде текстовых описаний, близких по смыслу к рассмотренным выше. Один атрибут может иметь несколько установленных в единицу значений флагов,
например, атрибут с идентификатором 05
отражающий количество переназначенных из-за сбоев секторов из резервной области, имеет установленные флаги SP+EC+OC – самосохраняющийся,
счетчик событий, обновляется при автономном и интерактивном режиме накопителя.
Для анализа состояния накопителя, пожалуй самым важным значением атрибута является Value - условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, при достижения которого, производитель не гарантирует его работоспособность - поле Threshold . Если значение Value приближается или становится меньше значения Threshold , - накопитель пора менять.
Перечень атрибутов и их значения жестко не стандартизированы и некоторые из них могут определяться изготовителем накопителя, но основная часть интерпретируются одинаково. Например, атрибут с идентификатором 05 (Reallocated sector count ) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, как для устройств производства компании Seagate Technology, так и для устройств производства Western Digital . Набор поддерживаемых атрибутов зависит от модели накопителя и может значительно отличаться по составу для разных моделей.
Наиболее распространенным программным средством для получения данных S.M.A.R.T в среде Linux, является утилита smartctl из комплекта smartmontools , как правило, входящего в состав устанавливаемого по умолчанию программного обеспечения любого дистрибутива. При необходимости, обновить версию, а также скачать документацию на английском языке можно на сайте проекта smartmontools.org .
Для работы с утилитой smartctl требуются права суперпользователя root .
Формат командной строки smartctl :
smartctl параметры устройство
Примеры использования smartctl
smartctl –help или smartctl --usage - отобразить подсказку об использовании команды.
Параметры smartctl :
-V, --version, --copyright, --license - отобразить версию, информацию копирайта и лицензии.
-i, --info - отобразить идентификационную информацию для устройства.
-g NAME, --get=NAME - отобразить параметры настроек диска (all, aam, apm, lookahead, security, wcache, rcache, wcreorder)
-a, --all - отобразить все данные SMART указанного диска.
-x, --xall - отобразить все технические данные для указанного диска.
--scan - выполнить поиск дисковых устройств.
-q TYPE, --quietmode=TYPE установить режим детализации вывода для smartctl (errorsonly, silent, noserial)
-d TYPE, --device=TYPE - установить тип устройства (ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N/E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test) Обычно установка типа устройства требуется в тех случаях, когда утилита smartctl не может определить его автоматически.
-b TYPE, --badsum=TYPE - задать реакцию на обнаружение ошибок контрольных сумм (warn, exit, ignore)
-r TYPE, --report=TYPE - опция предназначена для разработчиков smartmontools и позволяет получить детализированную информацию при выполнении транзакций функции управления устройствами ввода/вывода ioctl (ioctl, ataioctl, scsiioctl и уровень отладки). Подробности - man smartctl
-n MODE, --nocheck=MODE - режим запрета на выполнение тестов для режимов энергосбережения (never, sleep, standby, idle). Обычно используется для предотвращения запуска шпиндельного двигателя по команде smartctl.
-s VALUE, --smart=VALUE - отключение или включение SMART (on/off)
-o VALUE, --offlineauto=VALUE - запрет или разрешение автоматического выполнения тестов в неинтерактивном режиме (в режиме простоя накопителя), принимаемые значения - on/off
-S VALUE, --saveauto=VALUE автосохранение атрибутов (on/off)
-s NAME[,VALUE], --set=NAME[,VALUE] - запрет/разрешение параметров оборудования накопителя (aam,, apm,, lookahead,, security-freeze, standby,, wcache,, rcache,, wcreorder,)
-H, --health - отобразить состояние накопителя (SMART health status)
-c, --capabilities - отобразить информацию о поддерживаемых возможностях SMART указанного жесткого диска.
-A, --attributes - отобразить атрибуты SMART
-f FORMAT, --format=FORMAT
- задать формат отображаемых атрибутов SMART (old, brief, hex[,id|val]). В основном, влияет на формат отображаемых значений идентификаторов атрибутов и формат отображения их флагов:
old
- идентификаторы атрибутов выводятся в десятичной системе счисления, значения флагов отображаются в шестнадцатеричной и интерпретируются в виде текста.
hex
- то же, что и в предыдущем случае, но идентификаторы атрибутов отображаются в шестнадцатеричной системе счисления.
brief
- компактный вывод, идентификаторы отображаются в десятичной системе счисления, флаги отображаются в виде символов с расшифровкой в нижней части таблицы:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate POSR-- 114 100 006 - 78309029
. . . . . .
254 Free_Fall_Sensor -O--CK 100 100 000 - 0
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
-l TYPE, --log=TYPE - отобразить указанный журнал устройства (selftest, selective, directory[,g|s], xerror[,N][,error], xselftest[,N][,selftest],background, sasphy[,reset], sataphy[,reset], scttemp, scttempint,N[,p], scterc[,N,M], devstat[,N], ssd, gplog,N[,RANGE], smartlog,N[,RANGE]
-v N,OPTION , --vendorattribute=N,OPTION - установить параметр для определенного производителем атрибута с идентификатором N
-F TYPE, --firmwarebug=TYPE - адаптация программы для учета ошибок в аппаратной прошивке накопителя (none, nologdir, samsung, samsung2, samsung3, xerrorlba, swapid)
-P TYPE, --presets=TYPE - предустановки параметров диска. По умолчанию, обнаружив информацию о накопителе в своей базе, утилита smartctl , использует набор параметров, доступный для данной модели. Опция use - использовать предустановки для данного накопителя, ignore - не использовать, show - отобразить предустановки для данного диска, showall - отобразить предустановки для указанной модели. Примеры:
smartctl –P ignore /dev/hdb
- игнорировать предустановки для диска /dev/hdb;
smartctl –P show /dev/sdb
- отобразить предустановки для указанного диска;
smartctl –P showall ‘ST9250315AS’
- - отобразить предустановки для указанной модели
диска - ST9250315AS;
smartctl –P showall ‘ST3750515AS’ ‘SD15’
- отобразить предустановки для указанной
модели диска ST3750515AS с прошивкой SD15;
-B [+]FILE, --drivedb=[+]FILE - прочитать и изменить базу данных моделей дисков из файла FILE. Знак “+” перед именем файла, означает добавление новых записей в базу, перед уже существующими.
По умолчанию, база данных хранится в файле /usr/share/smartmontools/drivedb.h
DEVICE SELF-TEST OPTIONS =====
-t TEST, --test=TEST - запустить выполнение теста TEST Run test. TEST: offline, short, long, conveyance, force, vendor,N, select,M-N, pending,N, afterselect,
-C, --captive - выполнение тестов в режиме захвата накопителя. Используется совместно с параметром -t для тестов не в режиме offline . Использование данного параметра может вызвать занятость устройства на все время выполнения теста и привести к нарушению работы системы и потере данных. Не стоит использовать опцию -c для выполнения тестов накопителей с монтированными разделами. Для SCSI устройств данная опция означает выполнение встроенных тестов в режиме "Foreground mode" .
-X, --abort - принудительно завершить тест, выполняющийся без ключа --captive .
Примеры использования smartctrl.
smartctl --info /dev/sdb - отобразить идентификационную информацию для устройства /dev/sdb. Пример вывода команды:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:31 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled
smartctl --all /dev/hdа - отобразить все данные SMART для устройства /dev/hda
Пример отображаемых данных:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:45 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: (0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: (634) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: (1) minutes. Extended self-test routine recommended polling time: (102) minutes. Conveyance self-test routine recommended polling time: (2) minutes. SCT capabilities: (0x10bd) SCT Status supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 082 064 044 Pre-fail Always - 190274202 3 Spin_Up_Time 0x0003 096 096 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 72 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 070 060 030 Pre-fail Always - 11302732 9 Power_On_Hours 0x0032 073 073 000 Old_age Always - 24037 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 72 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 081 048 045 Old_age Always - 19 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 38 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 73 194 Temperature_Celsius 0x0022 019 052 000 Old_age Always - 19 (0 14 0 0) 195 Hardware_ECC_Recovered 0x001a 118 100 000 Old_age Always - 190274202 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 No self-tests have been logged. SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
smartctl -A -v 9,minutes /dev/hda - отобразить все данные атрибутов SMART для устройства /dev/hda и атрибут с идентификатором 9 (время нахождения во включенном состоянии) интерпретировать как внутреннее значение, задаваемое в минутах, а не в часах.
smartctl --smart=on --offlineauto=on --saveauto=on /dev/hda - включить SMART для диска /dev/hda, разрешить автоматическое выполнение оффлайн-тестов и самосохранение атрибутов. Команду можно выполнять на работающей системе. Фактически, это установка стандартных параметров эксплуатации для обычного дискового накопителя.
smartctl --test=long /dev/hda
- выполнить расширенные встроенные тесты для диска /dev/hda.Команду можно использовать на работающей системе. Для просмотра результатов выполнения тестов используется команда вывода внутреннего журнала после завершения теста
smartctl -l selftest /dev/hda
smartctl --attributes --log=selftest --quietmode=errorsonly /dev/had - отобразить данные внутреннего журнала самотестирования и атрибуты ошибок.
smartctl -s on -t offline /dev/hdc - включить SMART и выполнить оффлайн-тест для диска /dev/hdc. Если при тестировании будет обнаружена ошибка, то информация по ней будет записана во внутренний журнал, просмотреть который можно с использованием параметра -l error .
smartctl -q silent -a /dev/had - проверить данные SMART без вывода полученной информации.Обычно используется в скриптах. После выполнения команды проверяется код возврата (переменная $? командной оболочки)для определения факта выхода значения какого – либо атрибута за предельную величину или наличия записи об ошибках в журналах устройства.
smartctl -q errorsonly -H -l selftest /dev/had - выводить информацию только при наличии ошибочного состояния SMART или если какой-либо из внутренних тестов завершился с ошибкой.
smartctl -t select,10-100 -t select,30-300 -t afterselect,on -t pending,45 /dev/hda - выполнить внутренний тест в заданной области блоков LBA и после его завершения сканировать оставшуюся часть диска. Если при сканировании будет выполнено выключение питания, то продолжить его через 45 минут после включения.
smartctl --all --device=3ware,0 /dev/sda - получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware.
smartctl -a -d 3ware,0 /dev/twe0 - получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware RAID 6000/7000/8000.
smartctl -a -d 3ware,0 /dev/twa0 - получить данные SMART для первого ATA-диска, подключенного к RAID контроллеру 3ware RAID 9000
smartctl -t short -d 3ware,3 /dev/sdb - запустить выполнение коротких внутренних тестов для 4-го диска, второго дискового SCSI устройства /dev/sdb
smartctl -a -d hpt,1/3 /dev/sda - получить данные SMART диска, подключенного к 3-му каналу первого контроллера HighPoint RocketRAID
Расшифровка атрибутов S.M.A.R.T
Идентификаторы атрибутов указаны в десятичной системе счисления, а в скобках они же – в шестнадцатеричной.
Оценка технического состояния жесткого диска по данным S.M.A.R.T
Набор атрибутов поддерживаемых конкретной моделью жесткого диска, даже если он минимален, позволяет с высокой достоверностью определить техническое состояние и перспективы эксплуатации устройства. Можно определить время нахождения во включенном состоянии по значению атрибута 9 , а в совокупности со значением атрибута 12 - количество включений /выключений электропитания, и следовательно, – круглосуточный или периодический режим эксплуатации. Интенсивность использования, температурный режим, негативные внешние воздействия – все эти факты легко отслеживаются по абсолютным значениям соответствующих атрибутов. Подобным же образом, можно оценить и уровень износа оборудования, качество поверхности и тракта записи/чтения.
Минимально информативный контроль состояния дисков может выполняться даже на уровне BIOS. В случае достижения критического значения любого атрибута, характеризующего работоспособность, при включенном мониторинге состояния S.M.A.R.T в настройках BIOS, загрузка операционной системы приостанавливается и на экран выводится сообщение:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить факт критического состояния накопителя средствами Базовой Системы Ввода-Вывода (BIOS) при включении компьютера.
Техническое состояние жесткого диска, не достигшее критического порога, характеризуется абсолютным значением атрибутов, отражающих счетчики сбоев, обнаруженных и исправленных оборудованием накопителя.
Изменение абсолютных значений атрибутов нужно рассматривать в динамике, и в логической взаимосвязи друг с другом.
Выполнение встроенных тестов S.M.A.R.T
Набор встроенных тестов S.M.A.R.T определяется производителем и может значительно отличаться для разных моделей жестких дисков. В основном, встроенные тесты SMART представлены короткими тестами (short self-test) и длинными (extended sels-test). Короткие тесты выполняют сканирование небольшой части дисковой поверхности, определенной производителем, и выполняются, в среднем, около 1 минуты. Длинные тесты выполняют сканирование всей рабочей поверхности диска и могут выполняться, в зависимости от быстродействия и объема диска, даже несколько часов. Также, для современных дисков, можно выполнять селективные тесты (selective self-test), параметры которых задаются пользователем и тесты после транспортировки устройства (conveyance self-test). Выполнение тестов можно прервать, если не задан режим захвата накопителя (captive) и накопитель поддерживает команду отмены теста. Что касается режима захвата накопителя при выполнении тестов captive , то пользоваться им нужно осторожно, если диск используется системой.
Примеры:
smartctl --test=short /dev/sdb - запустить короткий тест. В ответ на команду, будет выведена информация:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Short self-test routine immediately in off-line mode". Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful. Testing has begun (previous test aborted). Please wait 1 minutes for test to complete. Test will complete after Fri Dec 5 16:08:09 2014 Use smartctl -X to abort test.
Что означает, что диску отправлена команда на выполнение короткого теста, диск ее воспринял успешно, тест будет продолжаться 1 минуту, и для принудительного его прекращения можно воспользоваться командой smartctl –X.
Результат выполнения теста можно проверить, просмотрев журнал тестов командой smartctl –l selftest . В ответ будет получена информация журнала selftest :
=== START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 831 -
Колонки журнала:
Num
- номер записи.
Test_Description
- описание теста.
Status
- статус завершения (выполнен без ошибок)
Remaining
- процент оставшегося времени до завершения теста, если он еще не завершен (00%)
LifeTime(hours)
- время работы накопителя с начала эксплуатации.
LBA_of_first_error
- номер логического блока LBA где обнаружена первая ошибка при выполнении теста. В данном примере, ошибок нет.
Для запуска длинного теста используется команда:
smartctl --test=long /dev/sdb
В ответ на команду выводится информация о начале теста:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Extended self-test routine immediately in off-line mode". Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful. Testing has begun. Please wait 70 minutes for test to complete. Test will complete after Fri Dec 5 17:15:44 2014
Как видно, длинный тест для данной модели накопителя будет выполняться 70 минут.
Результат выполнения можно проверить командой smartctl –l selftest /dev/sda
Список команд ATA для работы с S.M.A.R.T
SMART_READ_VALUES 0xd0 SMART_READ_THRESHOLDS 0xd1 SMART_AUTOSAVE 0xd2 SMART_SAVE 0xd3 SMART_IMMEDIATE_OFFLINE 0xd4 SMART_READ_LOG_SECTOR 0xd5 SMART_WRITE_LOG_SECTOR 0xd6 SMART_ENABLE 0xd8 SMART_DISABLE 0xd9 SMART_STATUS 0xda SMART_AUTO_OFFLINE 0xdb
Дополнительно по теме оборудования в Linux:
Новейшие накопители представлены интеллектуальными устройствами, способными анализировать свое состояние и своевременно информировать пользователя о неполадках. Для этого аппаратная часть включает оригинальную опцию S.M.A.R.T.

Назначение технологии SMART.
Львиная доля дисковых накопителей последних лет, функционирует с использованием технологии S.M.A.R.T. Сочетание расшифровывается как self-monitoring, analysis and reporting technology , что на русском звучит как механизм самоконтроля, анализа и отчетности. Ее первые разработки увидели свет в 1995 году и с тех пор технология постоянно совершенствуется.
С момента производства дисковый накопитель начинает считывать свое текущее состояние, определяя его с помощью специальных параметров или атрибутов. Они располагаются , доступ к которой имеет лишь встроенная программа. Просмотреть параметры позволяет отдельное ПО, чаще всего представленное утилитами от разработчиков конкретного жесткого диска. Через них в накопитель подаются вводные, после чего в журнале статистики появится информация о текущем состоянии диска.
В процессе эксплуатации накопителя, данные представленные в рамках параметров значения постоянно меняются. Параметры проходят путь с максимальных показателей, гарантирующих высокую производительность и эффективность до минимальных значений, связанных с высокой вероятностью выхода накопителя из строя.
Все представленные в рамках технологии S.M.A.R.T атрибуты имеет цифровой идентификатор. Как правило, он общий для накопителей различных версий, однако имеют место исключения. В данном отношении выделяется цифра 7, демонстрирующая ошибки в размещении головок на дисковую поверхность. Для цифровой идентификатор неактуален. В отличие от 7-ки, цифра 9, которая показывает общий период непосредственной работы накопителя за срок использования, ее поддерживают все типы дисков HDD и SSD.
Структура параметров, представлена несколькими полями, демонстрирующих состояние диска и его разделов в конкретный период. Предназначенные для считывания информации утилиты выводят на экран следующие параметры:
- ID – идентификационный номер
- name – название атрибута
- VAL – его текущее состояние
- Wrst – наихудший показатель за период эксплуатации
- Thresh – минимальный порог работоспособности
Показатели S.M.A.R.T
Существует несколько самых распространенных параметров. Они, за редким исключением, объединяют накопители большинства производителей, итак:
- Raw Read Error Rate – показатель числа ошибок считывания
- Throughput Performance – рабочая эффективность. Ее снижение указывает на необходимость замены
- Spin Up Time – период развертывания накопителя в рабочее состояние. Рост параметра демонстрирует изношенность или недостаток питания
- Start/Stop Count – показатель количества моментов развертывания диска, которое изначально ограничено его механической структурой
- Reallocated Sectors Count – атрибут отражает число запасных участков. Туда при неполадках перенаправляется информация. В идеале количество подобных действий должно составлять 0
- Read Channel Margin – канальный резерв. В наше время накопители обходятся без него
- Seek Error Rate – Отражение механического состояния накопителя, в числе прочего демонстрирует излишнюю вибрацию и перегрев
- Seek Time Performance – уровень оперативных возможностей, актуален лишь для дисков HDD
- Power-on Time – прогноз продолжительности функционирования накопителя исходя из периода эксплуатации. Максимальные показатели составляют 100 и с течением времени снижаются до 0
- Spin-Up Retry Count – количество дублирующих операций запуска. Их увеличение говорит об ошибках в механической структуре
Эти и другие атрибуты, идущие красным фоном, говорят о его критическом состоянии накопителя, что предполагает скорую поломку. Конкретного стандарта, объединяющего показатели параметров от различных производителей, не существует. В каждом случае нормальные значения индивидуальны, отражаясь в виде фона или статуса, где
- Good – хороший показатель
- Bad – плохой показатель.

Наряду с уже упомянутыми атрибутами следует уделять внимание таким параметрам как:
- Recalibration Retries – число дублей при рекаблировке. Их повышение свидетельствует о неполадках механики
- End-to-End error – Недостатки обменных операций
- Reported UNC Errors – неполадки, чье устранение ведется с помощью аппаратных средств
- G-sense error rate – количество механических воздействий на диск. Фиксирует неаккуратную установку, столкновения
- Reallocation Event Count – общий показатель операций перенаправления информации. Фиксирует удачные и неудачные операции
- Current Pending Sector Count – количество потенциальных участков накопителя, подлежащих замене
- Uncorrectable Sector Count – количество неисправных секторов, неподлежащих восстановлению
- UltraDMA CRC Error Count – неполадки перенаправления данных между накопителем и ПК
Проверка S.M.A.R.T
Параметры S.M.A.R.T проверяются при помощи специальных утилит от производителей жестких дисков. Существуют и универсальные программы для тестирования и проверки дисков. Среди них выделяются udisks, smartctl, hddscan, CrystalDiskInfo, Victoria, используя которые пользователь сможет оценить состояние жесткого диска. В некоторых случаях, а именно при работе с контроллерами RAID, получить дисковые атрибуты практически невозможно.


Минимальный уровень диагностики поддерживается на уровне BIOS. Если включен режим диагностики S.M.A.R.T., то при наличии критических значений атрибутов BIOS не позволит загрузиться операционной системе.
Итак, тестируя состояние жесткого диска, прежде всего внимание, уделяется указанным параметрам S.M.A.R.T . Основное назначение технологии – прогнозирование выхода их строя жесткого диска. При опасном отклонении показателей от нормы, имеет смысл переносить важную информацию на другие носители.
И, самое главное, даже если в S.MA.R.T. никаких ошибок нет и все хорошо, это не является гарантией, что диск не сломается, так что .
Рано или поздно (лучше, конечно, если рано) любой пользователь задает себе вопрос о том, как долго еще протянет установленный у него на компьютере жесткий диск и не пора ли присмотреть ему замену. Удивительного в этом ничего нет, поскольку жесткие диски в силу своих конструктивных особенностей являются наименее надежными среди компьютерных комплектующих. При этом именно на HDD у большинства пользователей хранится львиная доля самой разнообразной информации: документов, снимков, разнообразного ПО и т.д., вследствие чего неожиданный выход диска из строя - всегда трагедия. Конечно, нередко информацию на внешне «мертвых» жестких дисках можно восстановить, но не исключено, что эта операция влетит вам «в копеечку», да и нервов будет стоить немалых. Поэтому гораздо эффективнее попытаться предупредить потерю данных.
Как? Очень просто… Во-первых, не забывать о регулярном резервном копировании данных, а во-вторых, контролировать состояние дисков с помощью специализированных утилит. Несколько программ такого плана в ракурсе решаемых задач мы и рассмотрим в данной статье.
Контроль SMART-параметров и температуры
Все современные HDD и даже твердотельные накопители (SSD) поддерживают технологию S.M.A.R.T. (от англ. Self-Monitoring, Analysis, and Reporting Technology - технология самоконтроля, анализа и отчетности), которая была разработана основными производителями жестких дисков для увеличения надежности их продукции. Данная технология базируется на непрерывном мониторинге и оценке состояния жесткого диска встроенной аппаратурой самодиагностики (специальными сенсорами), а ее основное предназначение - своевременное выявление возможного выхода накопителя из строя.
Мониторинг состояния HDD в реальном времени
Ряд информационнодиагностических решений для диагностики и тестирования «железа», а также специальные мониторинговые утилиты используют технологию S.M.A.R.T. для наблюдения за текущим состоянием различных жизненно важных параметров, описывающих надежность и производительность жестких дисков. Они считывают соответствующие параметры непосредственно с сенсоров и термодатчиков, которыми оснащены все современные жесткие диски, анализируют полученные данные и отображают их в виде краткого табличного отчета с перечнем атрибутов. При этом часть утилит (Hard Drive Inspector, HDDlife, Crystal Disk Info и т.п.) не ограничивается отображением таблицы атрибутов (значения которых для неподготовленных пользователей непонятны) и дополнительно выводит краткую информацию о состоянии диска в более доступном для понимания виде.
Диагностировать состояние жесткого диска с помощью такого рода утилит проще простого - достаточно ознакомиться с краткой базовой информацией об установленных HDD: с основными данными о дисках в Hard Drive Inspector, неким условным процентом здоровья жесткого диска в HDDlife, индикатором «Техсостояние» в Crystal Disk Info (рис. 1) и т.д. В любой из подобных программ предоставляется минимум необходимой информации о каждом из установленных на компьютере HDD: данные о модели винчестера, его объеме, рабочей температуре, отработанном времени, а также уровне надежности и производительности. Эта информация дает возможность сделать определенные выводы о работоспособности носителя.
Рис. 1. Краткая информация о «здоровье» рабочего HDD
Следует настроить запуск мониторинговой утилиты одновременно со стартом операционной системы, скорректировать интервал времени между проверками S.M.A.R.T.-атрибутов, а также включить отображение температуры и «уровня здоровья» жестких дисков в системном трее. После этого для контроля за состоянием дисков пользователю достаточно будет время от времени поглядывать на индикатор в системном трее, где будет отображаться краткая информация о состоянии имеющихся в системе накопителей: уровне их «здоровья» и температуре (рис. 2). Кстати, рабочая температура - это не менее важный показатель, чем условный показатель здоровья HDD, ведь жесткие диски могут внезапно выйти из строя вследствие банального перегрева. Поэтому если жесткий диск нагревается выше 50 °C, то разумнее будет обеспечить ему дополнительное охлаждение.

Рис. 2. Отображение состояния жесткого диска
в системном трее программой HDDlife
Стоит отметить, что в ряде таких утилит предусмотрена интеграция с проводником Windows, благодаря чему на иконках локальных дисков в случае их исправности отображается зеленый значок, а при возникновении проблем значок становится красным. Так что забыть о состоянии здоровья жестких дисков вам вряд ли удастся. При таком постоянном мониторинге вы не сможете пропустить момент, когда с диском начнут возникать какието проблемы, ведь в случае выявления утилитой критических изменений атрибутов S.M.A.R.T. и/или температуры она заботливо оповестит об этом пользователя (сообщением на экране, звуковым сообщением и т.д. - рис. 3). Благодаря этому можно будет успеть скопировать данные с внушающего опасение носителя заблаговременно.

Рис. 3. Пример сообщения о необходимости немедленной замены диска
Использовать на практике решения S.M.A.R.T.-мониторинга для наблюдения за состоянием жестких дисков совершенно необременительно, ведь все подобные утилиты работают в фоновом режиме и требуют минимум аппаратных ресурсов, поэтому их функционирование ни в коей мере не помешает основному рабочему процессу.
Контроль S.M.A.R.T.-атрибутов
Продвинутые пользователи, разумеется, вряд ли ограничатся для оценки состояния жестких дисков просмотром краткого вердикта одной из представленных выше утилит. Оно и понятно, ведь по расшифровке атрибутов S.M.A.R.T. можно выявить причину сбоев и при необходимости предусмотрительно предпринять какието дополнительные меры. Правда, для самостоятельного контроля S.M.A.R.T.-атрибутов потребуется хотя бы кратко ознакомиться с технологией S.M.A.R.T.
В состав поддерживающих эту технологию жестких дисков ивключены интеллектуальные процедуры самодиагностики, поэтому они способны «сообщать» о своем текущем состоянии. Данная диагностическая информация предоставляется как коллекция атрибутов, то есть конкретных характеристик жесткого диска, используемых для анализа его производительности и надежности.
Бо льшая часть важных атрибутов имеет один и тот же смысл для дисков всех производителей. Значения данных атрибутов при нормальной работе диска могут варьироваться в некоторых интервалах. Для любого параметра производителем определено некое минимально безопасное значение, которое не может быть превышено при нормальных условиях эксплуатации. Однозначно определить критически важные и критически неважные для диагностики параметры S.M.A.R.T. проблематично. Каждый из атрибутов имеет свою информационную ценность и свидетельствует о том или ином аспекте в работе носителя. Однако в первую очередь следует обращать внимание на следующие атрибуты:
- Raw Read Error Rate - частота ошибок чтения данных с диска, возникших по вине оборудования;
- Spin Up Time - среднее время раскрутки шпинделя диска;
- Reallocated Sector Count - число операций переназначения секторов;
- Seek Error Rate - частота появления ошибок позиционирования;
- Spin Retry Count - число повторных попыток раскрутки дисков до рабочей скорости в случае неудачности первой попытки;
- Current Pending Sector Count - количество нестабильных секторов (то есть секторов, ожидающих процедуру переназначения);
- Offline Scan Uncorrectable Count - общее количество нескорректированных ошибок во время операций чтения/записи секторов.
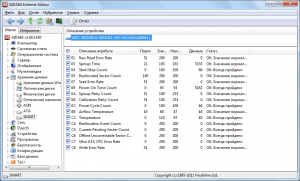
Обычно атрибуты S.M.A.R.T. отображаются в табличном виде с указанием имени атрибута (Attribute), его идентификатора (ID) и трех значений: текущего (Value), минимального порогового (Threshold) и самого низкого значения атрибута за всё время работы накопителя (Worst), а также абсолютного значения атрибута (Raw). Каждый атрибут имеет текущее значение, которое может быть любым числом от 1 до 100, 200 или 253 (общих стандартов для верхних границ значений атрибутов не предусмотрено). Значения Value и Worst у совершенно нового винчестера совпадают (рис. 4).

Рис. 4. Атрибуты S.M.A.R.T. у нового HDD
Приведенная на рис. 4 информация позволяет сделать вывод, что у теоретически исправного винчестера текущие (Value) и наихудшие (Worst) значения должны быть максимально близкими друг к другу, а значение Raw у большинства параметров (за исключением параметров: Power-On Time, HDA Temperature и некоторых других) должно приближаться к нулю. Текущее значение может со временем изменяться, что в большинстве случаев отражает ухудшение параметров жесткого диска, описываемых атрибутом. Это можно увидеть на рис. 5, где представлены фрагменты таблицы атрибутов S.M.A.R.T. для одного и того же диска - данные получены с интервалом в полгода. Как видим, в более свежей версии S.M.A.R.T. увеличилась частота ошибок при чтении данных с диска (Raw Read Error Rate), происхождение которых обусловлено аппаратной частью диска, и частота ошибок при позиционировании блока магнитных головок (Seek Error Rate), что, возможно, свидетельствует о перегреве винчестера и его неустойчивом положении в корзине. Если текущее значение какого-нибудь атрибута приближается или становится меньше порогового, то жесткий диск признается ненадежным, и его следует срочно менять. Например, падение значения атрибута Spin-Up Time (среднее время раскрутки шпинделя диска) ниже критического значения, как правило, сообщает о полном износе механики, вследствие чего диск больше не в состоянии поддерживать заданную производителем скорость вращения. Поэтому необходимо контролировать состояние HDD и периодически (например, раз в 2-3 месяца) проводить диагностику S.M.A.R.T. и сохранять полученную информацию в текстовом файле. В дальнейшем эти данные можно будет сравнить с текущими и сделать определенные выводы о развитии ситуации.

Рис. 5. Таблицы атрибутов S.M.A.R.T., полученные с полугодовым интервалом
(более свежая версия S.M.A.R.T. внизу)
При просмотре S.M.A.R.T.-атрибутов в первую очередь стоит обращать внимание на критически важные параметры, а также на параметры, выделенные отличными от базового цвета (чаще синего или зеленого) индикаторами. В зависимости от текущего состояния атрибута в выводимой утилитой S.M.A.R.T. таблице он обычно маркируется тем или иным цветом, что облегчает понимание ситуации. В частности, в программе Hard Drive Inspector цветовой индикатор может иметь зеленый, желтозеленый, желтый, оранжевый или красный цвет - зеленый и желтозеленый цвета говорят о том, что всё нормально (значение атрибута не менялось или несущественно менялось), а желтый, оранжевый и красный цвета сигнализируют об опасности (хуже всего красный цвет, который говорит о том, что значение атрибута достигло своего критического значения). Если какойто из критически важных параметров отмечен значком красного цвета, то нужно срочно заменить винчестер.
Просмотрим в программе Hard Drive Inspector таблицу S.M.A.R.T.-атрибутов того самого диска, краткая оценка которого мониторинговыми утилитами нами была приведена ранее. Из рис. 6 видно, что значения всех атрибутов в норме и все параметры промаркированы зеленым цветом. Аналогичную картину покажут и утилиты HDDlife и Crystal Disk Info. Правда, более профессиональные решения для анализа и диагностики HDD не столь лояльны и часто маркируют S.M.A.R.T.-атрибуты более придирчиво. К примеру, такие известные утилиты, как HD Tune Pro и HDD Scan, в нашем случае с подозрением отнеслись к атрибуту UltraDMA CRC Errors, который отображает число ошибок, возникающих при передаче информации по внешнему интерфейсу (рис. 7). Причина возникновения таких ошибок обычно связана с перекрученным и некачественным SATA-шлейфом, который, возможно, следует заменить.

Рис. 6. Таблица S.M.A.R.T.-атрибутов, полученная в программе Hard Drive Inspector

Рис. 7. Результаты оценки состояния S.M.A.R.T.-атрибутов
утилитами HD Tune Pro и HDD Scan
Для сравнения ознакомимся со S.M.A.R.T.-атрибутами очень древнего, но пока еще работающего HDD с периодически возникающими проблемами. Программе Crystal Disk Info доверия он не внушил - в индикаторе «Техсостояние» состояние диска было оценено как тревожное, а атрибут Reallocated Sector Count (Переназначенные сектора) оказался выделенным желтым цветом (рис. 8). Это весьма важный с точки зрения «здоровья» диска атрибут, обозначающий число секторов, переназначенных при обнаружении диском ошибки чтения/записи, при этой операции данные с поврежденного сектора переносятся в резервную область. Желтый цвет индикатора у параметра говорит о том, что оставшихся резервных секторов, которыми можно заменить сбойные, осталось мало, и вскоре переназначать вновь появляющиеся сбойные сектора окажется нечем. Проверим также, как оценивают состояние диска более серьезные решения, например широко используемая профессионалами утилита HDDScan, - но и здесь видим точно такой же результат (рис. 9).
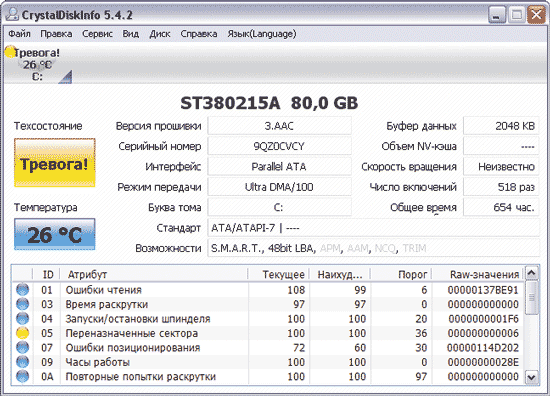
Рис. 8. Оценка проблемного жесткого диска в CrystalDiskInfo

Рис. 9. Результаты S.M.A.R.T.-диагностики HDD в HDDScan
Значит, с заменой такого жесткого диска тянуть явно не стоит, хотя он еще и может некоторое время послужить, правда операционную систему на данный жесткий диск устанавливать, конечно, нельзя. Стоит отметить, что при наличии большого числа переназначенных секторов скорость чтения/записи падает (вследствие лишних движений, которые приходится совершать магнитной головке), и диск начинает заметно тормозить.
Сканирование поверхности на bad-сектора
К сожалению, на практике одним контролем SMART-параметров и температуры не обойтись. При появлении мельчайших свидетельств о том, что с диском чтото не так (в случае периодического зависания программ, например при сохранении результатов, появлении сообщений об ошибках чтения и т.д.) необходимо просканировать поверхность диска на наличие нечитаемых секторов. Для проведения подобной проверки носителя можно воспользоваться, например, утилитами HD Tune Pro и HDDScan или диагностическими утилитами от производителей винчестеров, однако эти утилиты работают только со своими моделями жестких дисков, а потому рассматривать их мы не будем.
При использовании подобных решений существует опасность повреждения данных на сканируемом диске. С одной стороны, с информацией на диске, если накопитель действительно окажется неисправным, в ходе сканирования может случиться все что угодно. С другой стороны, нельзя исключать некорректных действий со стороны пользователя, по ошибке запускающего сканирование в режиме записи, в ходе которого происходит посекторное затирание данных с винчестера определенной сигнатурой, и на основании скорости этого процесса делается вывод о состоянии жесткого диска. Поэтому соблюдение определенных правил предосторожности совершенно необходимо: перед запуском утилиты нужно создать резервную копию информации и в ходе проверки действовать строго по инструкции разработчика соответствующего ПО. Для получения более точных результатов перед сканированием лучше закрыть все активные приложения и выгрузить возможные фоновые процессы. Кроме того, следует иметь в виду, что при необходимости тестирования системного HDD нужно загрузиться с флэшки и с нее запускать процесс сканирования либо совсем снять жесткий диск и подсоединить его к другому компьютеру, с которого и запускать тестирование диска.
В качестве примера с помощью HD Tune Pro проверим на плохие сектора поверхность HDD, который выше не внушил доверия утилите Crystal Disk Info. В этой программе для запуска процесса сканирования достаточно выбрать нужный диск, активировать вкладку Error Scan и щелкнуть на кнопке Start . После этого утилита приступит к последовательному сканированию диска, считывая сектор за сектором и отмечая на карте диска сектора разноцветными квадратиками. Цвет квадратиков в зависимости от ситуации может быть зеленым (нормальные сектора) или красным (bad-блоки) либо будет иметь некий промежуточный между этими цветами оттенок. Как видим из рис. 10, в нашем случае полноценных bad-блоков утилита не нашла, но тем не менее налицо солидное количество секторов с той или иной задержкой чтения (судя по их цвету). В дополнение к оному в средней части диска имеется небольшой блок секторов, цвет которого близок к красному - данные сектора пока утилитой не признаны сбойными, но они уже близки к этому и перейдут в категорию сбойных в самое ближайшее время.

Рис. 10. Сканирование поверхности на bad-сектора в HD Tune Pro
Протестировать носитель на плохие сектора в программе HDDScan сложнее, да и опаснее, поскольку в случае неверно выбранного режима информация на диске будет безвозвратно утрачена. Первым делом для запуска сканирования создают новую задачу, щелкнув по кнопке New Task и выбрав в списке команду Suface Tests . Затем нужно удостовериться, что выбран режим Read - этот режим устанавливается по умолчанию и при его использовании тестирование поверхности жесткого диска производится по чтению (то есть без удаления данных). После этого нажимают на кнопку Add Test (рис. 11) и дважды щелкают на созданной задаче RD-Read . Теперь в открывшемся окне можно наблюдать процесс сканирования диска на графике (Graph) или на карте (Map) - рис. 12. По завершении процесса получим примерно такие же результаты, что выше были продемонстрированы утилитой HD Tune Pro, но с более четкой интерпретацией: сбойных секторов нет (они отмечаются синим цветом), но в наличии три сектора со временем отклика более 500 мс (помечены красным цветом), которые и представляют реальную опасность. Что касается шести оранжевых секторов (время отклика от 150 до 500 мс), то это можно считать в пределах нормы, поскольку такая задержка отклика зачастую вызывается временными помехами в виде, например, работающих фоновых программ.

Рис. 11. Запуск тестирования диска в программе HDDScan

Рис. 12. Результаты сканирования диска в режиме Read с помощью HDDScan
В дополнение следует отметить, что при наличии небольшого количества bad-блоков можно попытаться улучшить состояние жесткого диска, убрав плохие сектора путем сканирования поверхности диска в режиме линейной записи (Erase) с помощью программы HDDScan. После такой операции некоторое время диск еще может эксплуатироваться, но, конечно, не в качестве системного. Однако уповать на чудо не стоит, поскольку HDD уже начал сыпаться, и нет никаких гарантий, что в ближайшее время количество дефектов не возрастет и накопитель окончательно не выйдет из строя.
Программы для S.M.A.R.T.-мониторинга и тестирования HDD
HD Tune Pro 5.00 и HD Tune 2.55
Разработчик: EFD Software
Размер дистрибутива: HD Tune Pro - 1,5 Мбайт; HD Tune - 628 Кбайт
Работа под управлением: Windows XP/Server 2003/Vista/7
Способ распространения: HD Tune Pro - shareware (15-дневная демо-версия); HD Tune - freeware (http://www.hdtune.com/download.html)
Цена: HD Tune Pro - 34,95 долл.; HD Tune - бесплатно (только для некоммерческого применения)
HD Tune - удобная утилита для диагностики и тестирования HDD/SSD (см. таблицу), а также карт памяти, USB-дисков и ряда других устройств хранения данных. Программа отображает детальную информацию о накопителе (версия прошивки, серийный номер, объем диска, размер буфера и режим передачи данных) и позволяет установить состояние устройства с использованием данных S.M.A.R.T. и мониторинга температуры. Кроме того, с ее помощью можно провести тестирование поверхности диска на наличие ошибок и оценить производительность устройства, проведя серию тестов (тесты скорости последовательного и случайного чтения/записи данных, тест файловой производительности, тест кэша и ряд Extra-тестов). Также утилита может использоваться для настройки AAM и безопасного удаления данных. Программа представлена в двух редакциях: коммерческой HD Tune Pro и бесплатной облегченной HD Tune. В редакции HD Tune доступен только просмотр детальной информации о диске и таблицы атрибутов S.M.A.R.T., а также сканирование диска на ошибки и тестирование на скорость в режиме чтения (Low level benchmark - read).
За мониторинг S.M.A.R.T.-атрибутов в программе отвечает вкладка Health - считывание данных с сенсоров производится через установленный промежуток времени, результаты отображаются в таблице. Для любого атрибута можно просмотреть историю его изменений в численном виде и на графике. Данные мониторинга автоматически записываются в лог, но никаких уведомлений пользователя при критических изменениях параметров не предусмотрено.
Что касается сканирования поверхности диска на предмет наличия поврежденных секторов, то за эту операцию отвечает вкладка Error Scan . Сканирование может быть быстрым (Quick scan) и глубоким - при быстрой проверке проверяется не весь диск, а только какая-то его часть (зона сканирования определяется через поля Start и End). Поврежденные сектора отображаются на карте диска в виде красных блоков.
HDDScan 3.3
Разработчик: Artem Rubtsov
Размер дистрибутива: 3,64 Мбайт
Работа под управлением: Windows 2000(SP4)/XP(SP2/SP3)/Server 2003/Vista/7
Способ распространения: freeware (http://hddscan.com/download/HDDScan-3.3.zip)
Цена: бесплатно
HDDScan - утилита для низкоуровневой диагностики жестких дисков, твердотельных накопителей и Flash-дисков с интерфейсом USB. Основное предназначение данной программы - тестирование дисков на наличие bad-блоков и сбойных секторов. Также утилита может использоваться для просмотра содержимого S.M.A.R.T., мониторинга температуры и изменения некоторых настроек жесткого диска: управления шумом (AAM), управления питанием (APM), принудительного запуска/остановки шпинделя накопителя и др. Программа работает без установки и может запускаться с портативного носителя, например флэшки.
Отображение S.M.A.R.T.-атрибутов и мониторинг температуры в HDDScan производится по требованию. Отчет S.M.A.R.T. содержит информацию о производительности и «здоровье» накопителя в виде стандартной таблицы атрибутов, температура накопителя отображается в системном трее и в специальном информационном окне. Отчеты можно распечатывать или сохранять в MHT-файле. Возможно проведение S.M.A.R.T.-тестов.
Проверка поверхности диска производится в одном из четырех режимов: Verify (режим линейной верификации), Read (линейного чтения), Erase (линейной записи) и Butterfly Read (режим чтения Butterfly). Для проверки диска на наличие bad-блоков обычно используется тест в режиме чтения (Read), с помощью которого происходит тестирование поверхности без удаления данных (вывод о состоянии накопителя делается на основании скорости посекторного чтения данных). При тестировании в режиме линейной записи (Erase) информация на диске затирается, но зато данный тест может несколько подлечить диск, избавив его от сбойных секторов. В любом из режимов тестировать можно весь диск полностью либо определенный его фрагмент (зона сканирования определяется указанием начального и конечного логических секторов - Start LBA и End LBA соответственно). Результаты тестирования представляются в виде отчета (вкладка Report) и отображаются на графике (Graph) и карте диска (Map) с указанием в числе прочего количества сбойных секторов (Bads) и секторов, время отклика которых при тестировании заняло более 500 мс (помечены красным цветом).
Hard Drive Inspector 4.13
Разработчик: AltrixSoft
Размер дистрибутива: 2,64 Мбайт
Работа под управлением: Windows 2000/XP/2003 Server/Vista/7
Способ распространения: shareware (14-дневная демо-версия - http://www.altrixsoft.com/ru/download/)
Цена : Hard Drive Inspector Professional - 600 руб.; Hard Drive Inspector for Notebooks - 800 руб.
Hard Drive Inspector - удобное решение для S.M.A.R.T.-мониторинга внешних и внутренних HDD. В данный момент на рынке программа предлагается в двух редакциях: базовой Hard Drive Inspector Professional и портативной Hard Drive Inspector for Notebooks; последняя включает всю функциональность версии Professional, и в то же время учитывает специфику мониторинга жестких дисков ноутбуков. Теоретически существует еще версия SSD, но она распространяется только в OEM-поставках.
Программа обеспечивает автоматическую проверку S.M.A.R.T.-атрибутов через указанные промежутки времени и по завершении выдает свой вердикт относительно состояния накопителя с отображением значений неких условных индикаторов: «надежности», «производительности» и «отсутствия ошибок» вместе с числовым значением температуры и температурной диаграммой. Также приводятся технические данные о модели диска, его емкости, общем свободном месте и времени работы в часах (днях). В расширенном режиме можно посмотреть информацию о параметрах диска (размер буфера, название прошивки и т.д.) и таблицу атрибутов S.M.A.R.T. Предусмотрены разные варианты информирования пользователя в случае критических изменений на диске. Дополнительно утилита может быть использована для снижения уровня шума, производимого жесткими дисками, и снижения энергопотребления HDD.
HDDlife 4.0
Разработчик: BinarySense, Ltd
Размер дистрибутива: 8,45 Мбайт
Работа под управлением: Windows 2000/XP/2003/Vista/7/8
Способ распространения: shareware (15-дневная демо-версия - http://hddlife.ru/rus/downloads.html)
Цена : HDDLife - бесплатно; HDDLife Pro - 300 руб.; HDDlife for Notebooks - 500 руб.
HDDLife - простая утилита, предназначенная для контроля состояния жестких дисков и SSD (с версии 4.0). Программа представлена в трех редакциях: бесплатной HDDLife и двух коммерческих - базовой HDDLife Pro и портативной HDDlife for Notebooks.
Утилита осуществляет мониторинг S.M.A.R.T.-атрибутов и температуры через заданные промежутки времени и по результатам анализа выдает компактный отчет о состоянии диска с указанием технических данных о модели диска и его емкости, отработанном времени, температуре, а также отображает условный процент его здоровья и производительности, что позволяет сориентироваться в ситуации даже новичкам. Более опытные пользователи дополнительно могут посмотреть таблицу S.M.A.R.T.-атрибутов. В случае проблем с жестким диском предусмотрена возможность настройки уведомлений; можно настроить программу так, чтобы при нормальном состоянии диска результаты проверки не отображались. Возможно управление уровнем шума HDD и энергопотреблением.
CrystalDiskInfo 5.4.2
Разработчик: Hiyohiyo
Размер дистрибутива: 1,79 Мбайт
Работа под управлением: Windows XP/2003/Vista/2008/7/8/2012
Способ распространения: freeware (http://crystalmark.info/download/index-e.html)
Цена: бесплатно
CrystalDiskInfo - простая утилита для S.M.A.R.T.-мониторинга состояния жестких дисков (включая многие внешние HDD) и SSD. Несмотря на бесплатность программа обладает всем необходимым функционалом для организации контроля состояния дисков.
Мониторинг дисков производится автоматически через указанное число минут или по требованию. По окончании проверки в системном трее отображается температура контролируемых устройств; детальная информация об HDD с указанием значений S.M.A.R.T.-параметров, температуры и вердикта программы о состоянии устройств доступна в главном окне утилиты. Имеется функционал для настройки пороговых значений для некоторых параметров и автоматического уведомления пользователя в случае их превышения. Возможно управление уровнем шума (AAM) и питанием (APM).
К сожалению, немалая часть современных HDD нормально работает чуть больше года, потом начинаются разного рода проблемы, которые со временем могут привести к потере данных. Подобной перспективы вполне можно избежать, если внимательно следить за состоянием жесткого диска, например, с помощью рассмотренных в статье утилит. Однако забывать о регулярном резервировании ценных данных также не стоит, поскольку мониторинговые утилиты, как правило, удачно прогнозируют выход диска из строя по вине «механики» (согласно статистике компании Seagate, из-за механических компонентов выходят из строя около 60% HDD), но они не в состоянии предсказать гибель накопителя вследствие неполадок с электронными компонентами диска.